Distributed Caching in a Data Grid
by Christopher Keene
Posted June 9, 2004
To take advantage of the compute scalability offered by grid computing, custom enterprise applications must be built using a data grid. The data grid is a way to "grid enable" any data-intensive application, using distributed caching to eliminate bottlenecks between databases and grid applications.
Grid computing delivers flexibility by enabling applications to be run on many small, inexpensive computers rather than a few big, expensive computers. Yet slow data access can throttle the performance of data-intensive applications running on grid computers. A data grid solves these problems by using distributed caching to eliminate bottlenecks between databases and grid applications.
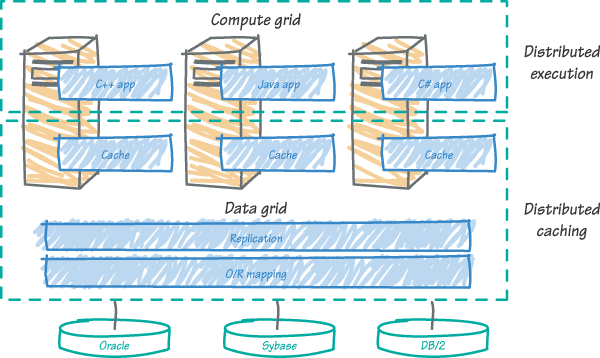
In the diagram, a data grid maps, replicates, and caches data from dissimilar relational data stores for use by object-oriented applications running on distributed servers. There are three critical data services that make up the data grid:
- Mapping transforms relational data into the appropriate object format to be used by Java, C++, or C# applications, which ensures all applications have consistent data.
- Replication ensures each cache has up-to-date data, even for dynamically changing information, which allows stateful applications to scale across multiple computers.
- Caching stages frequently used data in memory near the application, which eliminates redundant data queries and speeds performance.
The core technical concept for the data grid is to replicate data accessed frequently that is associated with an application to every grid computer where that application is running. Ensuring that each application has efficient access to data is the key to "grid-enabling" custom applications.
About the Author
Christopher Keene is CEO of Persistence Software, a provider of data management caching solutions. Contact Christopher at enterprisearchitect@fawcette.com.
Back to top
|